本博客由科研AI Agent实验室BenszResearch强力驱动!如何更快地访问本站?有需要可加电报群获得更多帮助。本博客用什么VPS?创作不易,请支持苯苯!推荐购买本博客的VIP喔,10元/年即可畅享所有VIP专属内容!
概览
- 本文围绕 前言 展开详细讨论
- 包含 22 个主要章节内容
- 文末提供总结与展望
前言
RSShub可以解决大多数的传统媒体和新媒体,但是对于微信公众号的支持是比较差的。
目前可行的方案有:
-
cooderl/wewe-rss: 🤗更优雅的微信公众号订阅方式,支持私有化部署、微信公众号RSS生成(基于微信读书):2025年前后发现的一个项目,值得关注。以后有机会我会折腾一下。
-
WeRss:https://werss.app。源稳定,可以全文抓取。不过要收费。

-
次幂数据:你可以在https://docs.rsshub.app/new-media.html#wei-xin查看。这个方法不错,可以抓到全文,并且可以抓到全部文章。缺点是文章更新比较慢,有时会延时数天。如果对时效性不太敏感的小伙伴可以使用。基于RSShub的特性也比较简单!你要登陆https://www.cimidata.com/search/account进行公众号ID的检索,一般一天可以免费查5次。一次爬取前20条最新记录。公众号ID就是链接中的
bid:

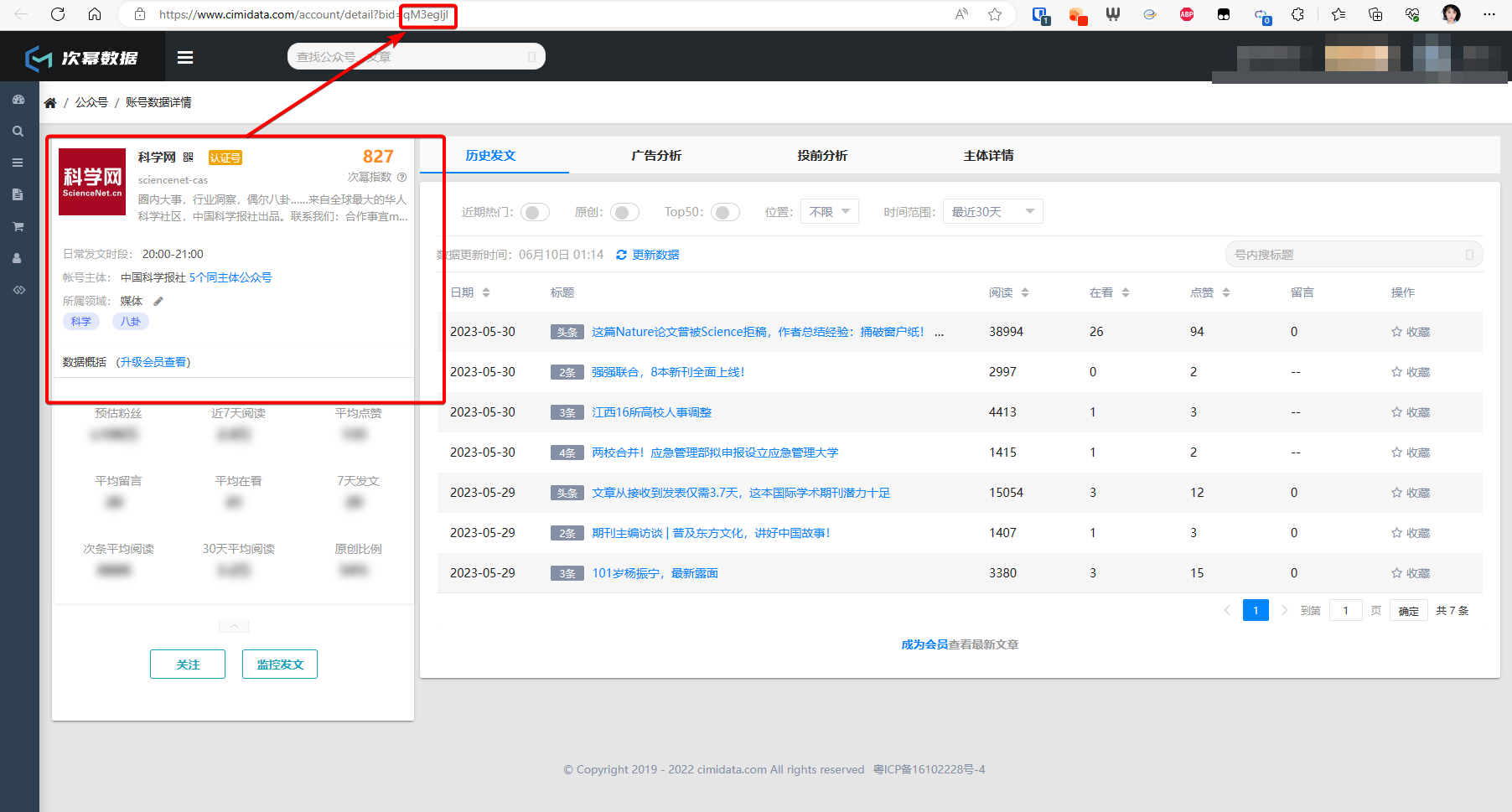
-
liuli:极客型项目。通过github托管的方式保存全文,RSS只推送github永久链接。通过搜狐微信进行最新文章的定位。对于1次发多篇文章的公众号,无法完全爬取
-
Feeddd:用户型项目。基于安卓,有点分布式的感觉。你可以去https://feeddd.org/feeds看看有没有自己的源可用。大多数源是可用,有些源虽然可用但无法稳定更新。如果你想要关注的公众号在上面可以找到,估计你也不需要使用liuli。毕竟你用liuli要自己折腾嘛!我感觉这个docker版liuli的配置还蛮复杂的。
-
docker-com_wechat_robot:基于ComWeChatRobot的docker镜像。感兴趣可以看看该教程《EFB-WECHAT-COMWECHAT 教程》。该方案对VPS资源消耗比较大,我不想折腾了(~ ̄▽ ̄)~
目前可行性较差的方案:
-
EFB v2 :比如《为一个基于 efb v2 的公众号抓取输出方案提供支持》所描述的那样,通过Telegram机器人和全新微信帐号进行交互;通过比较复杂的修改可以实现全文抓取。不过,如果通过https://web.wechat.com验证帐号无法登录web微信的用户均无法使用此方法,用户面太窄。EFB的开发者暂时还没有进一步解决方案。
-
huginn:目前托管在http://huginnio.herokuapp.com/scenarios上的scenarios没一个可以起作用。自己写的难度太高了,根本不是小白用户可以胜任的。
-
wechat-feeds:已经停止更新,不稳定。
-
其它项目:wemp.app、CareerEngine、优读来源、微阅读来源
我个人的经验,如果你要添加某个公众号,可以使用以下流程:
-
如果可以在知乎、微博等其它平台可以找到对应的号,优先使用其它平台的RSS源。
-
如果在非微信平台找不到对应的号,且你不介意付费,用WeRss。
-
如果不想付费,可以:(1)在Feeddd里找一下有没有稳定更新的源;(2)通过次幂数据找到公众号ID,通过RSShub获取源;(3)尝试
liuli。
总之,我将liuli方案放到最后,毕竟这个方案你要自己折腾一个docker镜像,操作上比较复杂;而且它只能爬最新一条记录,对于一次性大量更新的公众号无法实现完全爬取。另外,liuli查看全文时访问的Github Page,所以如果你无法访问github的话,liuli不适合你喔!
最新的使用体验我会在底部的日志中更新。大家如果是新人准备入手liuli,可以先看看日志,觉得符合自己的需求后再使用。下面我们进行docker版liuli的安装!
测试环境
uname -a #Linux racknerd-XXX 5.4.0-28-generic #32-Ubuntu SMP Wed Apr 22 17:40:10 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
docker --version # Docker version 20.10.14, build a224086
docker-compose --version # Docker Compose version v2.4.1
准备工作
一般环境
按需修改工作目录:
work=~/docker/liuli && mkdir -p $work/{liuli_config,mongodb_data} && cd $work
按需修改端口(最好不要改),开启防火墙:
sudo ufw allow 8765/tcp comment 'liuli' && sudo ufw reload &&
sudo ufw allow 27027/tcp comment 'liuli-db' && sudo ufw reload
提前拉取镜像:
docker pull liuliio/api:v0.1.3 &&
docker pull liuliio/schedule:v0.2.4 &&
docker pull mongo:3.6
企业微信
你需要一个企业微信的小程序作为Liuli分发器。当然,钉钉、Telegram也是可以的,不过我还没试过。喜欢折腾的童鞋可以试试看!
你可以在https://work.weixin.qq.com/wework_admin/register_wx中注册一个企业微信,大致界面如下:
成功注册后,主界面大致如下。点击右上角框框所在名字,可以进入界面查看ID:
企业ID就在最下方有显示:
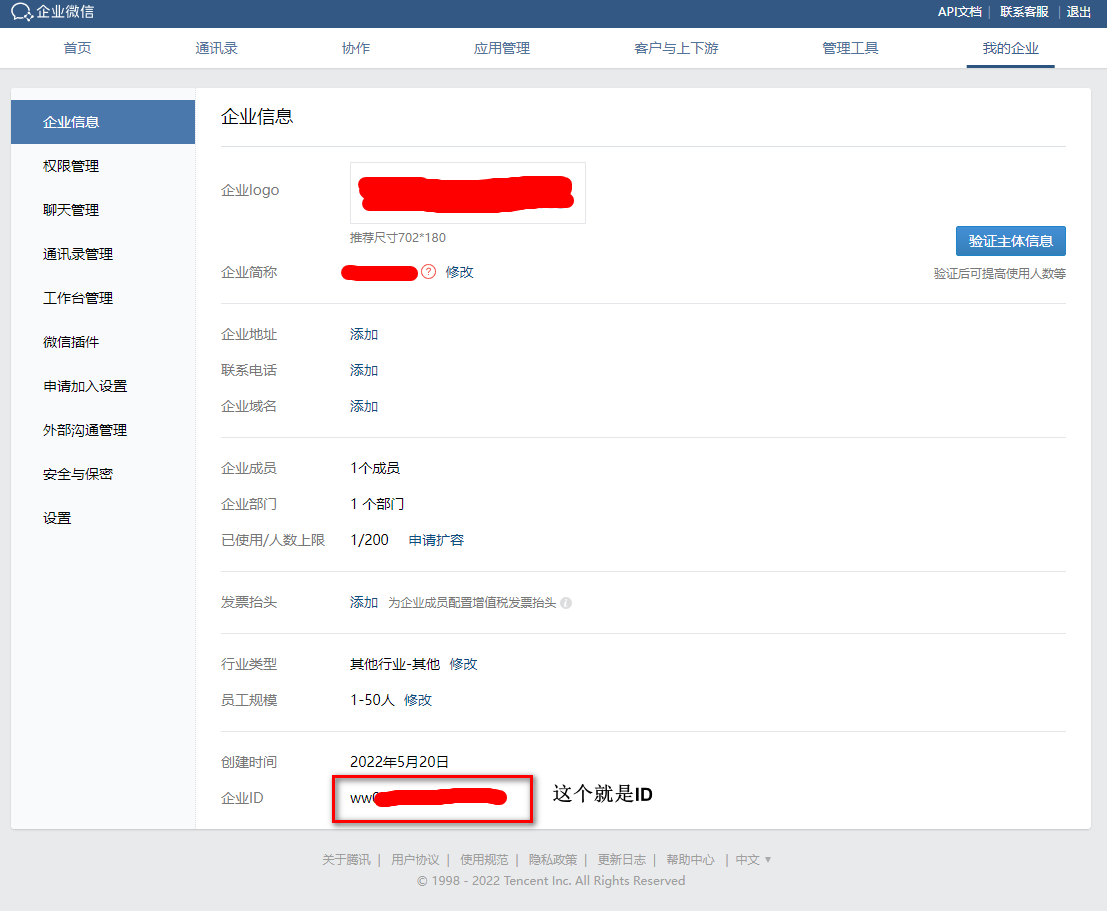
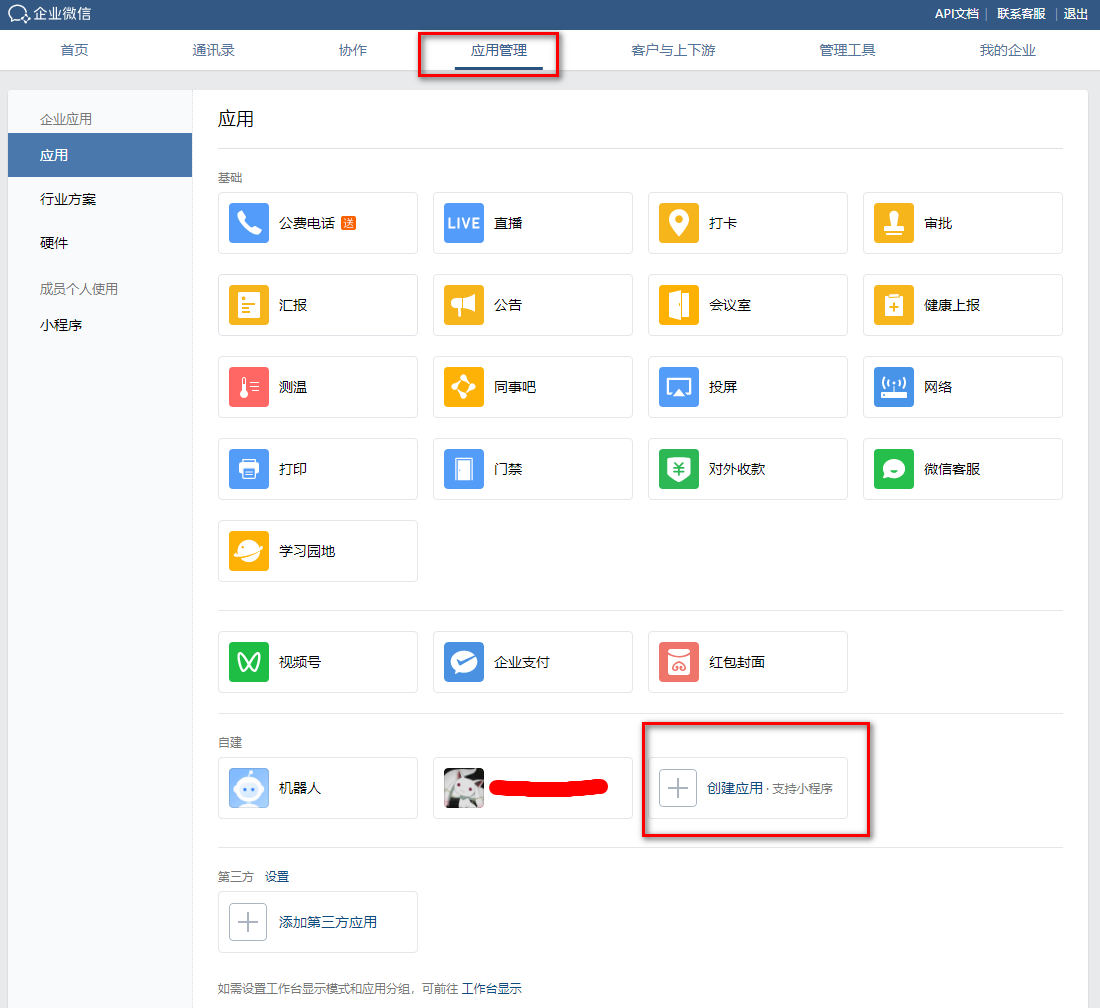
然后,在应用管理——自建中创建一个小程序。点击小程序图标,结合手机的企业微信查看AgentID和Secret:
更多操作也可以参考此文:https://mp.weixin.qq.com/s/rxoq97YodwtAdTqKntuwMA。
总之,你需要在企业微信和小程序中获取3个信息:
- 企业ID:对应
pro.env的LL_WECOM_ID。 - AgentId:对应
pro.env的LL_WECOM_AGENT_ID。 - Secret:对应
pro.env的LL_WECOM_SECRET。
Github仓库
主要参考https://github.com/liuli-io/liuli/blob/main/docs/04.%E5%A4%87%E4%BB%BD%E5%99%A8%E9%85%8D%E7%BD%AE.md的示范。这个Github仓库主要用于托管微信公众号文章的html页面。就是说,你在RSS阅读器中所点中的链接,会跳转到Github托管的页面。
首先,要生成Token以便让应用可以通过API接口访问Github仓库。权限请勾选 repo 和 user。这个过程要验证你的Github密码。如果你不会的话,百度Google一下好吧!老手的话估计都是常规操作了。
接着,建立liuli_backup仓库。你可以随便创建一个README.md,以便后面可以访问Page设置:
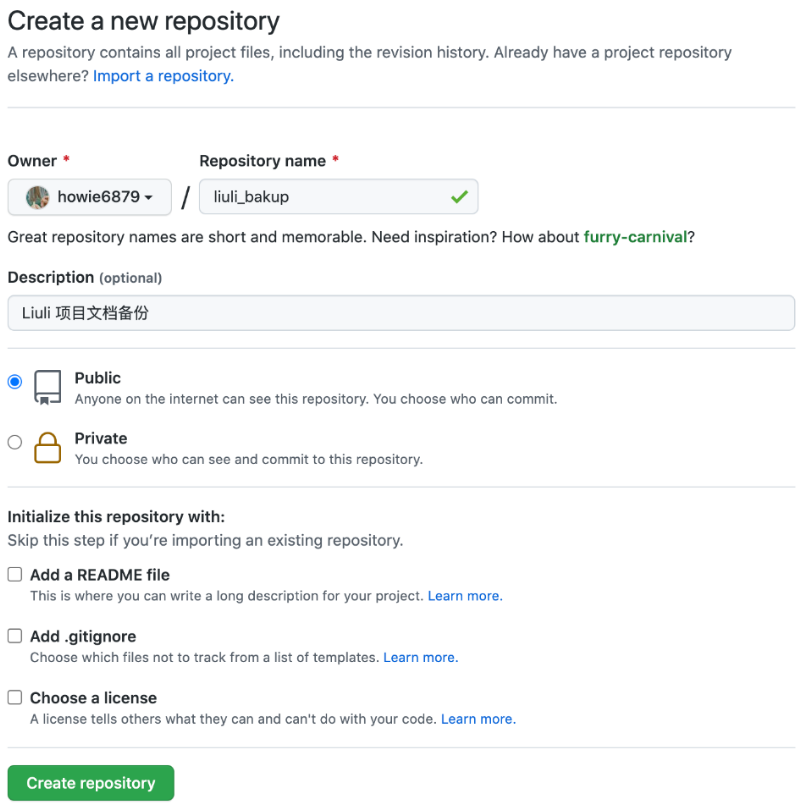
你可以在Settings里添加Github Page相关设置:
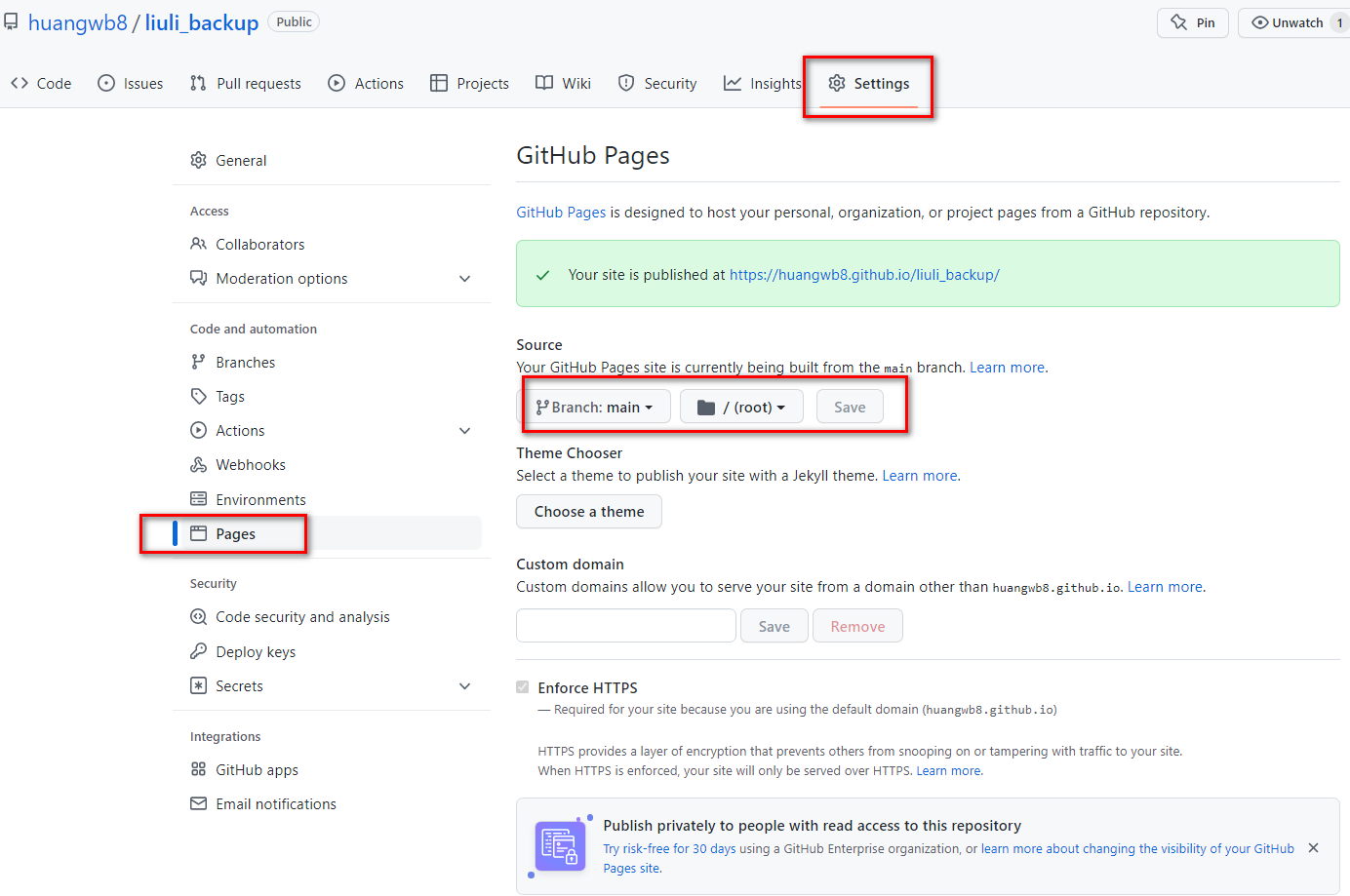
这个Github仓库主要是对应pro.env里的3个参数:
- LL_GITHUB_TOKEN
- LL_GITHUB_REPO
- LL_GITHUB_DOMAIN
具体的格式往后看就知道了!
pro.env
我主要是参考https://github.com/liuli-io/liuli/blob/main/docs/02.%E7%8E%AF%E5%A2%83%E5%8F%98%E9%87%8F.md进行填写。如果你十分了解里面的参数,可以随意修改。下面我提交的是我觉得比较合适的内容。修改$work/pro.env文件的内容如下:
PYTHONPATH=${PYTHONPATH}:${PWD}
LL_M_USER="liuli"
LL_M_PASS="liuli" # 按需修改
LL_M_HOST="liuli_mongodb"
LL_M_PORT="27017"
LL_M_DB="admin"
LL_M_OP_DB="liuli"
LL_FLASK_DEBUG=0
LL_HOST="0.0.0.0"
LL_HTTP_PORT=8765
LL_WORKERS=1
# 填写IP。这里我填的是docker0的ip。
LL_DOMAIN="http://172.17.0.1:8765"
# 分发器
LL_WECOM_ID="ww0000000000000" # 按需填写
LL_WECOM_AGENT_ID="1000001" # 按需填写
LL_WECOM_SECRET="fdC0000000000000000000000000000000000000" # 按需填写
# 这个最好配,因为你的rss如果访问的话,是访问这个github上的佩芬地址
LL_GITHUB_TOKEN="ghp_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" # 按需填写
LL_GITHUB_REPO="<your-github-user>/liuli_backup" # 按需填写
LL_GITHUB_DOMAIN="https://<your-github-user>.github.io/liuli_backup" # 按需填写
default.json
参考https://github.com/liuli-io/liuli/blob/main/liuli_config/wechat.json修改修改$work/liuli_config/default.json文件的内容如下。其中,wechat_list就是你想要订阅的微信公众号的名字。其它参数,你知道什么意思可以改,不知道就保持默认即可。
{
"name": "wechat",
"author": "liuli_team",
"doc_source": "liuli_wechat",
"collector": {
"wechat": {
"wechat_list": [
"老胡的储物柜", "PT邀请码网"
],
"delta_time": 5,
"spider_type": "sg_ruia",
"spider_type_des": "sg_playwright"
}
},
"processor": {
"before_collect": [],
"after_collect": [{
"func": "ad_marker",
"cos_value": 0.6
}, {
"func": "to_rss",
"doc_source_list": ["liuli_wechat"],
"link_source": "github"
}]
},
"sender": {
"sender_list": ["wecom"],
"query_days": 7,
"delta_time": 3
},
"backup": {
"backup_list": ["github", "mongodb"],
"query_days": 7,
"delta_time": 3,
"init_config": {},
"after_get_content": [{
"func": "str_replace",
"before_str": "data-src=\"",
"after_str": "src=\"https://images.weserv.nl/?url="
}]
},
"schedule": {
"period_list": [
"00:10",
"12:10",
"21:10"
]
}
}
在schedule里的时间,可以通过period_list设置更加频繁的更新。比如:
"period_list": [
"00:00",
"06:00",
"09:00",
"12:00",
"15:00",
"18:00",
"21:00"
]
另外,在processor里看下列内容:
{
"func": "to_rss",
"doc_source_list": ["liuli_wechat"],
"link_source": "github"
}
这里link_source选择的是github。我们其实也在本地mongodb保存了html页面。那么,是否也可以通过设置,使得我们最终访问的是本地的html?大家试试看,我觉得用github挺好的,就不尝(zhe)试(teng)了。
配置yaml文件
不了解docker的小伙伴请先看:《Docker系列 配置Docker全局环境》;《Docker系列 了解Docker Compose的配置文件》。
新建docker-compose.yml文件:
vim $work/docker-compose.yml
添加以下内容:
version: "3"
services:
liuli_api:
image: liuliio/api:v0.1.3
restart: always
container_name: liuli_api
ports:
- "8765:8765"
volumes:
- ./pro.env:/data/code/pro.env
links:
- liuli_mongodb
depends_on:
- liuli_mongodb
networks:
- liuli-network
liuli_schedule:
image: liuliio/schedule:v0.2.4
restart: always
container_name: liuli_schedule
volumes:
- ./pro.env:/data/code/pro.env
- ./liuli_config:/data/code/liuli_config
links:
- liuli_mongodb
depends_on:
- liuli_mongodb
networks:
- liuli-network
liuli_mongodb:
image: mongo:3.6
restart: always
container_name: liuli_mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=liuli
- MONGO_INITDB_ROOT_PASSWORD=liuli # 按需修改
ports:
- "27027:27017"
volumes:
- ./mongodb_data:/data/db
command: mongod
networks:
- liuli-network
networks:
liuli-network:
driver: bridge
这里注意,如果你改动了liuli_api的端口号或者是MONGO_INITDB_ROOT_PASSWORD,在pro.env也要做相应的改动。
上线服务:
docker-compose up -d
查看日志:
# 全部
docker-compose logs -f
# schedule
docker logs liuli_schedule -f
这里有一些实际成功运行的日志:
liuli_mongodb | 2022-05-20T12:51:22.574+0000 I NETWORK [listener] connection accepted from 192.168.208.4:45442 #4 (2 connections now open)
liuli_api | [2022-05-20 20:22:58 +0800] [7] [INFO] Listening at: http://0.0.0.0:8765 (7)
liuli_api | [2022-05-20 20:22:58 +0800] [7] [INFO] Using worker: gevent
liuli_api | [2022-05-20 20:22:58 +0800] [8] [INFO] Booting worker with pid: 8
liuli_api | [2022:05:20 20:23:00] INFO Liuli API server(v0.1.3) started successfully :)
...
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 🤗 微信公众号文章更新完毕(11/11)!
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 采集器执行完毕!
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 处理器(after_collect): 开始执行!
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 处理器(after_collect): ad_marker 正在执行...
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 处理器(after_collect): to_rss 正在执行...
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 😀 为liuli_wechat: 老胡的储物柜 的 2 篇文章生成RSS成功!
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 😀 为liuli_wechat: PT邀请码网 的 1 篇文章生成RSS成功!
liuli_schedule | [2022:05:20 21:11:32] INFO Liuli 处理器(after_collect): 执行完毕!
...
liuli_schedule | [2022:05:20 21:12:53] INFO Liuli 处理器(backup:after_get_content): str_replace 正在执行...
liuli_schedule | [2022:05:20 21:12:53] INFO Liuli Backup(mongodb): liuli_wechat/PT邀请码网/万由UNAS远程访问设置教程(U-Anywhere和DDNS).html 已存在!
ddns-go & NPM
不了解Nginx Proxy Manager用法的小伙伴,请看《Docker系列 两大神器NPM和ddns-go的安装》。
在ddns-go或者域名托管商后台添加域名:https://liuli.domain.com(这个根据自己的实际情况)。最后NPM的配置如下图所示:
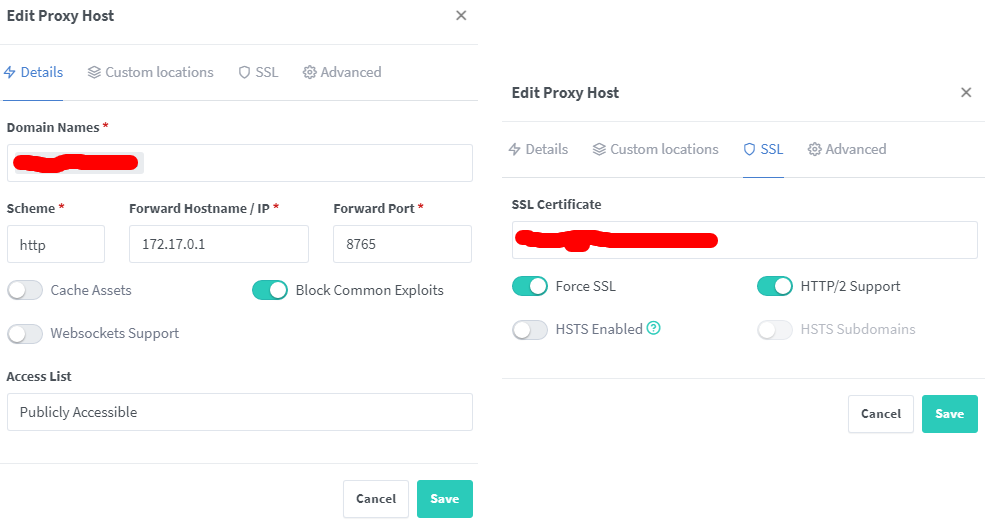
这里注意,172.17.1.0是docker0的ip地址,与pro.env文件中的LL_DOMAIN是相对应的。
获取RSS地址
比如,我想获得老胡的储物柜这个公众号的RSS订阅地址,其为:
https://liuli.domain.com/rss/liuli_wechat/老胡的储物柜
如果你直接在chrome上访问这个网址,它有时候是无法访问的。可能要过一会才可以查看。那么,应该如何快速验证它是否可以成功运行呢?
方法1:在你的VPS中输入(你在chrome里复制地址出来,中文会转为下面的格式):
curl 'https://domain.com/rss/liuli_wechat/%E8%80%81%E8%83%A1%E7%9A%84%E5%82%A8%E7%89%A9%E6%9F%9C/'
结果类似于:
<?xml version='1.0' encoding='UTF-8'?>
<feed xmlns="http://www.w3.org/2005/Atom">
<id>老胡的储物柜</id>
<title>老胡的储物柜</title>
<updated>2022-05-20T13:11:32.151798+00:00</updated>
<author>
<name>Liuli</name>
</author>
<generator uri="https://github.com/liuli-io/liuli" version="v0.2.4">Liuli</generator>
<entry>
<id>liuli_wechat - 老胡的储物柜 - 我的周刊(第040期)</id>
<title>我的周刊(第040期) </title>
<updated>2022-05-20T13:11:32.153026+00:00</updated>
<author>
<name>liuli_wechat - howie6879</name>
</author>
<content/>
<link href="https://<your-github-user>.github.io/liuli_backup/liuli_wechat/老胡的储物柜/%E6%88%91%E7%9A%84%E5%91%A8%E5%88%8A%EF%BC%88%E7%AC%AC040%E6%9C%9F%EF%BC%89.html" rel="alternate"/>
<published>2022-05-20T18:17:29+08:00</published>
</entry>
<entry>
<id>liuli_wechat - 老胡的储物柜 - 我的周刊(第039期)</id>
<title>我的周刊(第039期) </title>
<updated>2022-05-20T13:11:32.152063+00:00</updated>
<author>
<name>liuli_wechat - howie6879</name>
</author>
<content/>
<link href="https://<your-github-user>.github.io/liuli_backup/liuli_wechat/老胡的储物柜/%E6%88%91%E7%9A%84%E5%91%A8%E5%88%8A%EF%BC%88%E7%AC%AC039%E6%9C%9F%EF%BC%89.html" rel="alternate"/>
<published>2022-05-13T23:03:35+08:00</published>
</entry>
</feed>
方法2:直接在TTRSS等RSS阅读器里订阅和调试。这个就不细说了。
最后,你可以像我一样,通过TTRSS进行订阅。如果你不会使用TTRSS,请参考《Docker系列 安装个人RSS服务TTRSS 手机完美适配》。你有其它RSS阅读器也是可以的。成功订阅后,其推送的是公众号文章的链接而不是全文,你打开链接后可以查看托管在github上的html文件,和在微信上看的效果是类似的:
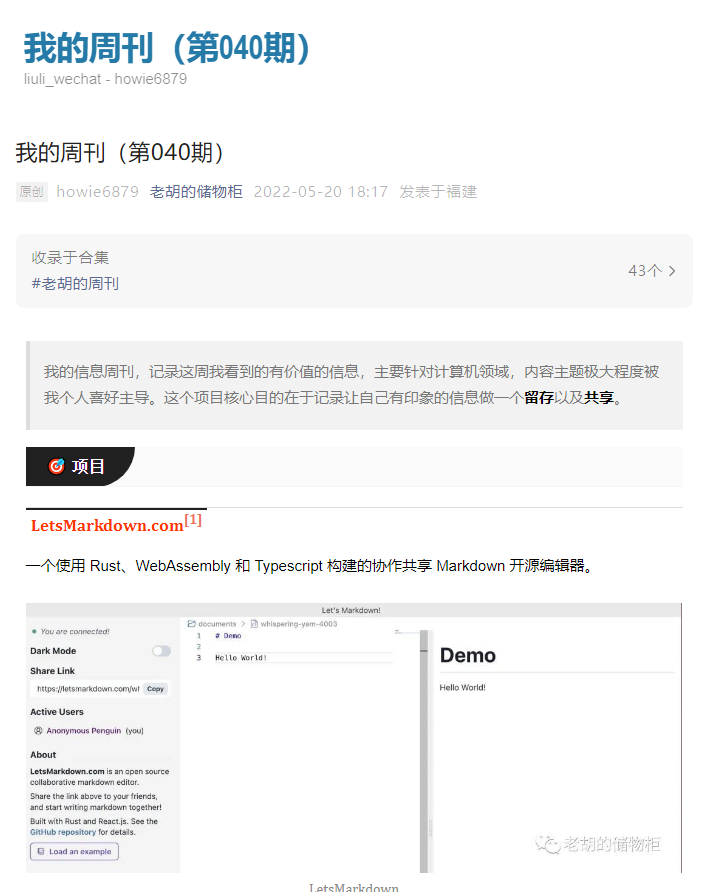
小结
我发现在企业微信里也会收到通知。如果你不想在手机上看,到后台设置消息免打扰即可。虽然很多优秀作者都在微信公众号上发文,但由于微信公众号的闭源生态,想要获取微信公众号的RSS源比较困难。
暂时是这些吧,有什么问题大家可以在评论区留言。或者在liuli仓库提交issue。
参考
- 基于Liuli构建纯净的RSS公众号信息流:https://mp.weixin.qq.com/s/rxoq97YodwtAdTqKntuwMA
- liuli的github仓库:https://github.com/liuli-io/liuli
日志
2025-05-18
- 发现一种微信公众号订阅的方案: cooderl/wewe-rss: 🤗更优雅的微信公众号订阅方式,支持私有化部署、微信公众号RSS生成(基于微信读书)
2022-05-21
-
某些微信号无法正常地爬取,有点遗憾。暂不知如何解决。
-
频繁更新的微信号无法完全爬取,存在记录缺失。这是由于搜狐微信平台的天然缺陷所致,估计是无法修复的。
2022-05-20
liuli_schedule在运作时可出现下列报错,但似乎对RSS无影响。暂不知Error的来源,可能是内置python脚本的问题。持续观察中。
liuli_schedule | [2022:05:20 23:24:52] ERROR SGWechatSpider <Item: Failed to get target_item's value from html.>
liuli_schedule | Traceback (most recent call last):
liuli_schedule | File "/root/.local/share/virtualenvs/code-nY5aaahP/lib/python3.9/site-packages/ruia/spider.py", line 197, in _process_async_callback
liuli_schedule | async for callback_result in callback_results:
liuli_schedule | File "/data/code/src/collector/wechat/sg_ruia_start.py", line 58, in parse
liuli_schedule | async for item in SGWechatItem.get_items(html=html):
liuli_schedule | File "/root/.local/share/virtualenvs/code-nY5aaahP/lib/python3.9/site-packages/ruia/item.py", line 127, in get_items
liuli_schedule | raise ValueError(value_error_info)
liuli_schedule | ValueError: <Item: Failed to get target_item's value from html.>
---------------
完结,撒花!如果您点一下广告,可以养活苯苯😍😍😍

楼主现在这个liuli我配置完成之后,订阅rss只会出现标题没有内容是怎么了呀
这个是正常的,都是点开标题看。 这已经是很不错了 (~ ̄▽ ̄)~
大佬您好,想问一下你的cloudflare是怎么保持通畅的,我的经常时断时续,有时候用飞机可以上
没听懂你的问题。 Cloudflare通畅是指?
东西不错,感觉手上难度还是有点大! 加上不稳定,只能先观望了!
目前来看,只有付费业务才比较稳。免费的项目,老实说,次幂勉勉强强;liuli有重大的缺陷,坐等开发者大佬了(๑•̀ㅁ•́ฅ)
也希望这样了。
记得最开始用即刻类似的,现在也没了
微信和头条都一样,技术太强太封闭。没有稳定方案可以解决。有些方案暂时可以,很快也会被封杀掉的。
很好,我选择werss
毕竟稳定用好几年了,不折腾。其他方法都用过,能成功的也是坚持不过一个月~~~
是的,微信RSS源目前确实没有完美的免费方案,有点遗憾 ̄﹃ ̄